Speech
textToSpeech
- Type:
true| {
voiceName?: string,
lang?: string,
pitch?: number,
rate?: string,
volume?: number,
audio?: AudioResponse
}
When the chat receives a new text message - your device will automatically read it out.
voiceName is the name of the voice that will be used to read out the incoming message. Please note that different Operating Systems
support different voices. Use the following code snippet to see the available voices for your device: window.speechSynthesis.getVoices()
lang is used to set the utterance language. See the following QA for the available options.
pitch sets the pitch at which the utterance will be spoken at.
volume set the volume at which the utterance will be spoken at.
audio is used to control audio file response message behaviour.
Text to speech is using SpeechSynthesis Web API
which is supported differently across different devices.
Your mouse needs to be focused on the browser window for this to work.
Example
- Sample code
- Full code
<deep-chat textToSpeech='{"volume": 0.9}'></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
textToSpeech='{"volume": 0.9}'
introMessage='{"text": "Send a message to hear the response."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
speechToText
-
Type:
true| {
webSpeech?:true|WebSpeechOptions,
azure?: AzureOptions,
textColor?: TextColor,
displayInterimResults?: boolean,
translations?: {[key: string]: string},
commands?: Commands,
button?: ButtonStyles,
stopAfterSubmit?: boolean,
submitAfterSilence?: SubmitAfterSilence,
events?: SpeechEvents
} -
Default: {webSpeech: true, stopAfterSubmit: true}
Transcribe your voice into text and control chat with commands.
webSpeech utilises Web Speech API to transcribe your speech.
azure utilises Azure Cognitive Speech Services API to transcribe your speech.
textColor is used to set the color of interim and final results text.
displayInterimResults controls whether interim results are displayed.
translations is a case-sensitive one-to-one mapping of words that will automatically be translated to others.
commands is used to set the phrases that will trigger various chat functionality.
button defines the styling used for the microphone button.
stopAfterSubmit is used to toggle whether the recording stops after a message has been submitted.
submitAfterSilence configures automated message submit functionality when the user stops speaking.
events is used to listen to speech functionality events.
Web Speech API is not supported in this browser.
Example
- Sample code
- Full code
<deep-chat
speechToText='{
"webSpeech": true,
"translations": {"hello": "goodbye", "Hello": "Goodbye"},
"commands": {"resume": "resume", "settings": {"commandMode": "hello"}},
"button": {"position": "outside-start"}
}'
></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{
"webSpeech": true,
"translations": {"hello": "goodbye", "Hello": "Goodbye"},
"commands": {"resume": "resume", "settings": {"commandMode": "hello"}},
"button": {"position": "outside-start"}
}'
introMessage='{"text": "Click the microphone to start transcribing your speech."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
If the microphone recorder is set - this will not be enabled.
Speech to text functionality is provided by the Speech To Element library.
Support for webSpeech varies across different browsers, please check the Can I use Speech Recognition API section.
(The yellow bars indicate that it is supported)
Types
AudioResponse
- Type: {
autoPlay?: boolean,displayAudio?: boolean,displayText?: boolean}
Controls the behaviour of an audio file in a response message:
autoPlay toggles if the audio is played automatically.
displayAudio toggles if the audio message bubble is displayed.
displayText toggles if the text in the same response message is displayed.
- Sample code
- Full code
<deep-chat speechToText='{"audio": {"autoPlay": true}}'></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{"audio": {"autoPlay": true}}'
introMessage='{"text": "Click the microphone to start transcribing your speech."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
WebSpeechOptions
- Type: {
language?: string}
language is used to set the recognition language. See the following QA
for the full list.
Web Speech API is not supported in this browser.
Example
- Sample code
- Full code
<deep-chat speechToText='{"webSpeech": {"language": "en-US"}}'></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{"webSpeech": {"language": "en-US"}}'
introMessage='{"text": "Click the microphone to start transcribing your speech."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
This service stops after a brief period of silence due to limitations in its API and not Deep Chat.
AzureOptions
-
Type: {
region: string,
retrieveToken?: () => Promise<string>,
subscriptionKey?: string,
token?: string,
language?: string,
autoLanguage?:{type?: "AtStart" | "Continuous",languages: string[]},
endpointId?: string,
deviceId?: string,
stopAfterSilenceMs?: number
} -
Default: {stopAfterSilenceMs: 25000 (25 seconds)}
This object requires region and either retrieveToken, subscriptionKey or the token properties to be defined with it:
region is the location/region of your Azure speech resource.
retrieveToken is a function used to retrieve a new token for the Azure speech resource. It is the recommended property to use as
it can retrieve the token from a secure server that will hide your credentials. Check out the retrieval example below
and starter server templates.
subscriptionKey is the subscription key for the Azure speech resource.
token is a temporary token for the Azure speech resource.
language is a BCP-47 string value to denote the recognition language. You can find the full
list here.
autoLanguage is used to configure automatic language identification
based on a list of candidate languages. type defines if the language can be identified in the first 5 seconds ("AtStart") or any time ("Continuous").
endpointId is the id of a customized speech model.
deviceId is the id of specific media device. More info here.
stopAfterSilenceMs is the milliseconds of silence required for the microphone to automatically turn off.
To use the Azure Speech To Text service - please add the Speech SDK to your project.
See EXAMPLES.
Example
- Sample code
- Full code
<deep-chat
speechToText='{
"azure": {
"subscriptionKey": "resource-key",
"region": "resource-region",
"language": "en-US",
"stopAfterSilenceMs": 5000
}
}'
></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{
"azure": {
"subscriptionKey": "resource-key",
"region": "resource-region",
"language": "en-US",
"stopAfterSilenceMs": 5000
}
}'
errorMessages='{
"overrides": {"speechToText": "Azure Speech To Text can not be used in this website as you need to set your credentials."}
}'
introMessage='{"text": "Azure Speech To Text can't be used in this website as you need to set your credentials."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
Location of speech service credentials in Azure Portal:
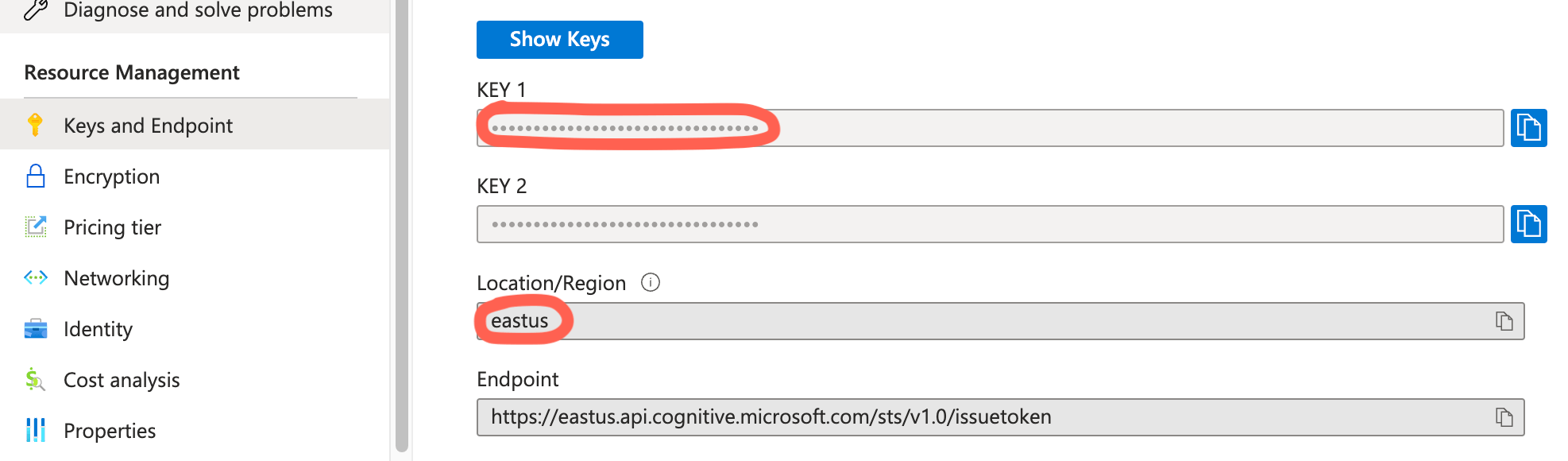
The subscriptionKey and token properties should only be used for local/prototyping/demo purposes ONLY. When you are ready to deploy your application,
please switch to using the retrieveToken property. Check out the example below and starter server templates.
Retrieve token example
- Code
speechToText.speechToText = {
region: 'resource-region',
retrieveToken: async () => {
return fetch('http://localhost:8080/token')
.then((res) => res.text())
.then((token) => token);
},
};
TextColor
- Type: {
interim?: string,final?: string}
This object is used to set the color of interim and final results text.
Example
- Sample code
- Full code
<deep-chat speechToText='{"textColor": {"interim": "green", "final": "blue"}}'></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{"textColor": {"interim": "green", "final": "blue"}}'
introMessage='{"text": "Click the microphone to start transcribing your speech."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
Commands
-
Type: {
stop?: string,
pause?: string,
resume?: string,
removeAllText?: string,
submit?: string,
commandMode?: string,
settings?:{substrings?: boolean,caseSensitive?: boolean}
} -
Default: {settings: {substrings: true, caseSensitive: false}}
This object is used to set the phrases which will control chat functionality via speech.
stop is used to stop the speech service.
pause will temporarily stop the transcription and will re-enable it after the phrase for resume is spoken.
removeAllText is used to remove all input text.
submit will send the current input text.
commandMode is a phrase that is used to activate the command mode which will not transcribe any text and will wait for a command to be executed. To leave
the command mode - you can use the phrase for the resume command.
substrings is used to toggle whether command phrases can be part of spoken words or if they are whole words. E.g. when this is set to true and your command phrase is "stop" -
when you say "stopping" the command will be executed. However if it is set to false - the command will only be executed if you say "stop".
caseSensitive is used to toggle if command phrases are case sensitive. E.g. if this is set to true and your command phrase is "stop" - when the service recognizes
your speech as "Stop" it will not execute your command. On the other hand if it is set to false it will execute.
Example
- Sample code
- Full code
<deep-chat
speechToText='{
"commands": {
"stop": "stop",
"pause": "pause",
"resume": "resume",
"removeAllText": "remove text",
"submit": "submit",
"commandMode": "command",
"settings": {
"substrings": true,
"caseSensitive": false
}}}'
></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{
"commands": {
"stop": "stop",
"pause": "pause",
"resume": "resume",
"removeAllText": "remove text",
"submit": "submit",
"commandMode": "command",
"settings": {
"substrings": true,
"caseSensitive": false
}}}'
introMessage='{"text": "Click the microphone to start transcribing your speech. Command mode activation phrase is `command`."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
ButtonStyles
This object is used to define the styling for the microphone button.
It contains the same properties as the MicrophoneStyles object
and an additional commandMode property which sets the button styling when the command mode is activated.
Example
- Sample code
- Full code
<deep-chat
speechToText='{
"button": {
"commandMode": {
"svg": {
"styles": {
"default": {
"filter":
"brightness(0) saturate(100%) invert(70%) sepia(70%) saturate(4438%) hue-rotate(170deg) brightness(92%) contrast(98%)"
}}}},
"active": {
"svg": {
"styles": {
"default": {
"filter":
"brightness(0) saturate(100%) invert(10%) sepia(97%) saturate(7495%) hue-rotate(0deg) brightness(101%) contrast(107%))"
}}}},
"default": {
"svg": {
"styles": {
"default": {
"filter":
"brightness(0) saturate(100%) invert(77%) sepia(9%) saturate(7093%) hue-rotate(32deg) brightness(99%) contrast(83%)"
}}}}},
"commands": {
"removeAllText": "remove text",
"commandMode": "command"
}
}'
></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{
"button": {
"commandMode": {
"svg": {
"styles": {
"default": {
"filter":
"brightness(0) saturate(100%) invert(70%) sepia(70%) saturate(4438%) hue-rotate(170deg) brightness(92%) contrast(98%)"
}}}},
"active": {
"svg": {
"styles": {
"default": {
"filter":
"brightness(0) saturate(100%) invert(10%) sepia(97%) saturate(7495%) hue-rotate(0deg) brightness(101%) contrast(107%)"
}}}},
"default": {
"svg": {
"styles": {
"default": {
"filter":
"brightness(0) saturate(100%) invert(77%) sepia(9%) saturate(7093%) hue-rotate(32deg) brightness(99%) contrast(83%)"
}}}}},
"commands": {
"removeAllText": "remove text",
"commandMode": "command"
}
}'
introMessage='{"text": "Click the microphone to start transcribing your speech. Command mode activation phrase is `command`."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
You can use the CSSFilterConverter tool to generate filter values for the icon color.
SubmitAfterSilence
- Type:
true|number
Automatically submit the input message after a period of silence.
This property accepts the value of true or a number which represents the milliseconds of silence
required to wait before a messaget is submitted. If this is set to true the default milliseconds is 2000.
Example
- Sample code
- Full code
<deep-chat speechToText='{"submitAfterSilence": 3000}'></deep-chat>
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<deep-chat
speechToText='{"submitAfterSilence": 3000}'
introMessage='{"text": "Click the microphone to start transcribing your speech."}'
style="border-radius: 8px"
demo="true"
></deep-chat>
When using the default Web Speech API - the recording will
automatically stop after 5-7 seconds of silence and will ignore custom timeouts that are higher than this.
SpeechEvents
- Type: {
onStart?:() => void,
onStop?:() => void,
onResult?:(text: string, isFinal: boolean) => void,
onPreResult?:(text: string, isFinal: boolean) => void,
onCommandModeTrigger?:(isStart: boolean) => void,
onPauseTrigger?:(isStart: boolean) => void
}
This object contains multiple properties that can be attached with functions that will be
triggered when the corresponding event occurs.
onStart is triggered when speech recording starts.
onStop is triggered when speech recording stops.
onResult is triggered when the latest speech segment is transcribed and inserted into chat's text input.
onPreResult is triggered when the latest speech segment is transcribed and before it is inserted into chat's text input. This is
particularly useful for executing commands.
onCommandModeTrigger is triggered when command mode is initiated and stopped.
onPauseTrigger is triggered when the pause command is initiated and then stopped via the resume command.
Example
- Function
chatElementRef.speechToText = {
events: {
onResult: (text, isFinal) => { console.log(text, isFinal); };
}
}
Demo
This is the example used in the demo video. When replicating - make sure to add the Speech SDK to your project and add your resource properties.
- Code
<!-- This example is for Vanilla JS and should be tailored to your framework (see Examples) -->
<div style="display: flex">
<deep-chat
speechToText='{
"azure": {
"subscriptionKey": "resource-key",
"region": "resource-region"
},
"commands": {
"stop": "stop",
"pause": "pause",
"resume": "resume",
"removeAllText": "remove text",
"submit": "submit",
"commandMode": "command"
}}'
errorMessages='{
"overrides": {"speechToText": "Azure Speech To Text can not be used in this website as you need to set your credentials."}
}'
style="margin-right: 30px"
demo="true"
></deep-chat>
<deep-chat
speechToText='{
"commands": {
"azure": {
"subscriptionKey": "resource-key",
"region": "resource-region"
},
"stop": "stop",
"pause": "pause",
"resume": "resume",
"removeAllText": "remove text",
"submit": "submit",
"commandMode": "command"
}}'
errorMessages='{
"overrides": {"speechToText": "Azure Speech To Text can not be used in this website as you need to set your credentials."}
}'
demo="true"
></deep-chat>
</div>